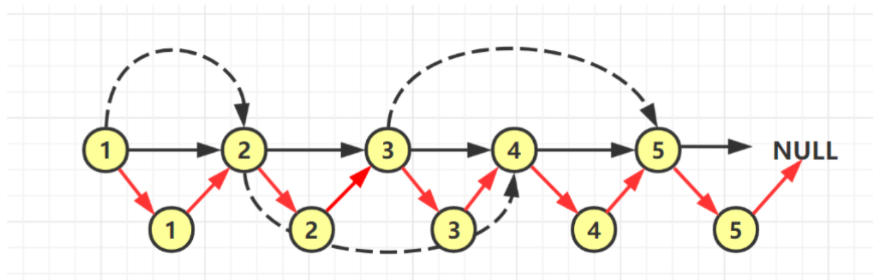
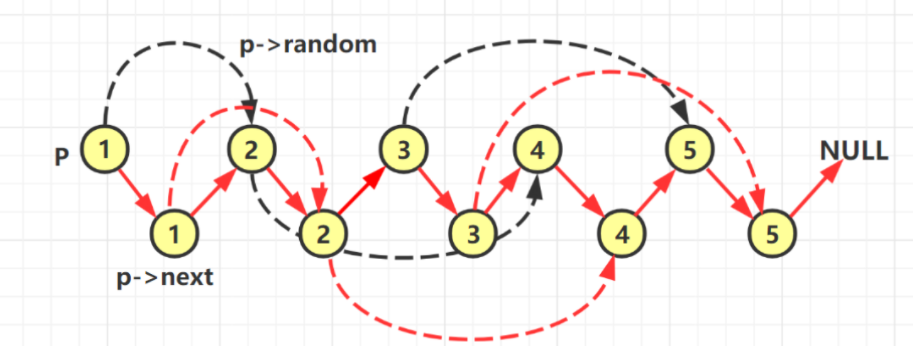
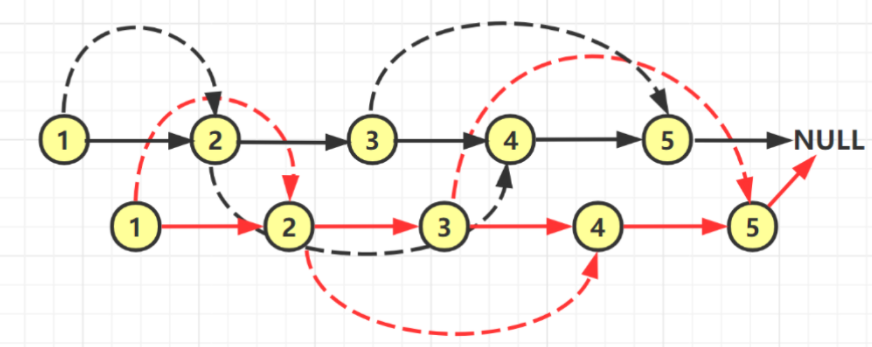
从整个矩阵的右上角开始枚举,假设当前枚举的数是 x: 如果 x 等于 target,则说明我们找到了目标值,返回true; 如果 x 小于 target,则 x 左边的数一定都小于 target,我们可以直接排除当前一整行的数; 如果 x 大于 target,则 x 下边的数一定都大于 target,我们可以直接排序当前一整列的数。
时间复杂度:O(n + m)
核心代码:
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution { public: boolfindNumberIn2DArray(vector<vector<int>>& matrix, int target){ if (matrix.empty() || matrix[0].empty()) returnfalse; int i = 0, j = matrix[0].size() - 1; while (i < matrix.size() && j >= 0) { if (matrix[i][j] == target) returntrue; if (matrix[i][j] > target) j--; else i++; } returnfalse; } };
// 翻转链表 classSolution { public: vector<int> reversePrint(ListNode* head){ vector<int> ans; for (auto i = head; i; i = i->next) { ans.push_back(i->val); } reverse(ans.begin(), ans.end()); return ans; } };
intmain(){ int n; // 循环构造链表 ListNode* dummy = newListNode(-1); auto cur = dummy; while (cin >> n, n != -1) { auto p = newListNode(n); cur->next = p; cur = p; }
// 循环输出原链表 for (auto i = dummy->next; i; i = i->next) { cout << i->val << ' '; } cout << endl;
// 输出结果 vector<int> ans; Solution solution; ans = solution.reversePrint(dummy->next); for (auto x : ans) { cout << x << ' '; } cout << endl; return0; }
TreeNode* dfs(int pl, int pr, int il, int ir){ // 如果左边大于右边了,说明到叶子节点了 if (pl > pr) returnnullptr; // 根节点就是前序遍历的第一个点 auto root = newTreeNode(preorder[pl]); // 根节点在中序遍历中的位置 int k = hash[preorder[pl]];
// 递归前序遍历和中序遍历得到左右子树的根节点 auto left = dfs(pl + 1, pl + k - il, il, k - 1); auto right = dfs(pl + k - il + 1, pr, k + 1, ir);
while (stk.size()) { auto i = stk.top(); cache.push(i); stk.pop(); } int k = cache.top(); cache.pop(); while (cache.size()) { auto i = cache.top(); stk.push(i); cache.pop(); } return k; } };
/** * Your CQueue object will be instantiated and called as such: * CQueue* obj = new CQueue(); * obj->appendTail(value); * int param_2 = obj->deleteHead(); */
classSolution { public: intfib(int n){ longlong a = 0, b = 1, c; while (n--) { c = a % 1000000007 + b % 1000000007; a = b; b = c; } return a % 1000000007; } };
classSolution { public: intfib(int n){ longlong a = 0, b = 1, c; while (n--) { c = a % 1000000007 + b % 1000000007; a = b; b = c; } return a % 1000000007; } };
classSolution { public: intnumWays(int n){ longlong a = 1, b = 1, c; while (n--) { c = a % 1000000007 + b % 1000000007; a = b; b = c; } return a % 1000000007; } };
classSolution { public: intminArray(vector<int>& numbers){ int n = numbers.size() - 1; while (n > 0 && numbers[n] == numbers[0]) n--; if (numbers[n] >= numbers[0]) return numbers[0]; int l = 0, r = n; while (l < r) { int mid = l + r >> 1; if (numbers[mid] >= numbers[0]) l = mid + 1; else r = mid; } return numbers[l]; } };
暴力做法:时间复杂度:O(n)
1 2 3 4 5 6 7 8 9 10 11
classSolution { public: intminArray(vector<int>& numbers){ if (numbers.empty()) return0; int minv = numbers[0]; for (int i = 1; i < numbers.size(); i++) { minv = min(minv, numbers[i]); } return minv; } };
classSolution { public: boolexist(vector<vector<char>>& board, string word){ for (int i = 0; i < board.size(); i++) { for (int j = 0; j < board[i].size(); j++) { // 其中的0是已经有0个字母合法,当合法字母数量与word字符数量相同时,就可以返回true了 if (dfs(board, 0, i, j, word)) { returntrue; } } } returnfalse; }
booldfs(vector<vector<char> > &board, int u, int i, int j, string &word){ // 指定边界条件 if (board[i][j] != word[u]) returnfalse; // 这里一定要记得-1,因为u是从0开始的,笔者之前忘记-1了,调试过后才发现是这里错了 if (u == word.size() - 1) returntrue;
// 将走过的路径保存下来,并且置为'*',避免走回头路 char t = board[i][j]; board[i][j] = '*';
// 枚举四个方向 for (int k = 0; k < 4; k++) { int a = i + dx[k], b = j + dy[k]; if (a >= 0 && a < board.size() && b >= 0 && b < board[0].size()) { if (dfs(board, u + 1, a, b, word)) { returntrue; } } }
classSolution { public: boolexist(vector<vector<char>>& board, string word){ for (int i = 0; i < board.size(); i++) { for (int j = 0; j < board[i].size(); j++) { // 其中的0是已经有0个字母合法,当合法字母数量与word字符数量相同时,就可以返回true了 if (dfs(board, 0, i, j, word)) { returntrue; } } } returnfalse; }
booldfs(vector<vector<char> > &board, int u, int i, int j, string &word){ // 指定边界条件 if (board[i][j] != word[u]) returnfalse; // 这里一定要记得-1,因为u是从0开始的,笔者之前忘记-1了,调试过后才发现是这里错了 if (u == word.size() - 1) returntrue;
// 将走过的路径保存下来,并且置为'*',避免走回头路 char t = board[i][j]; board[i][j] = '*';
// 枚举四个方向 for (int k = 0; k < 4; k++) { int a = i + dx[k], b = j + dy[k]; if (a >= 0 && a < board.size() && b >= 0 && b < board[0].size()) { if (dfs(board, u + 1, a, b, word)) { returntrue; } } }
intmovingCount(int m, int n, int k){ // 判断一下边界条件 if (!m || !n) return0; int res = 0; // 定义一个二维数组st,用来储存已经走过的位置 vector<vector<bool>> st(m, vector<bool>(n, false)); // 用来存放遍历到的每一个坐标,所以用pair类型的队列 queue<pair<int, int>> q;
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
// 首先给队列里面放入初始位置的坐标 q.push({0, 0}); while (q.size()) { auto t = q.front(); q.pop();
for (int i = 0; i < 4; i++) { int x = t.first + dx[i], y = t.second + dy[i]; if (x >= 0 && x < m && y >= 0 && y < n) { q.push({x, y}); } } } return res; } };
intmovingCount(int m, int n, int k){ // 判断一下边界条件 if (!m || !n) return0; int res = 0; // 定义一个二维数组st,用来储存已经走过的位置 vector<vector<bool>> st(m, vector<bool>(n, false)); // 用来存放遍历到的每一个坐标,所以用pair类型的队列 queue<pair<int, int>> q;
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
// 首先给队列里面放入初始位置的坐标 q.push({0, 0}); while (q.size()) { auto t = q.front(); q.pop();
for (int i = 0; i < 4; i++) { int x = t.first + dx[i], y = t.second + dy[i]; if (x >= 0 && x < m && y >= 0 && y < n) { q.push({x, y}); } } } return res; } };
intmain(){ Solution solution; int m, n, k; cin >> m >> n >> k; cout << solution.movingCount(m, n, k) << endl; return0; }
classSolution { public: intcuttingRope(int n){ if (n <= 3) return1 * (n - 1); int res = 1; if (n % 3 == 1) res = 4, n -= 4; elseif (n % 3 == 2) res = 2, n -= 2; while (n) res *= 3, n -= 3; return res; } };
核心代码(也可以先把3减掉,看剩下的是多少):
1 2 3 4 5 6 7 8 9 10 11 12 13
intcuttingRope(int n){ int res = 1; if (n == 3) return2; if (n == 2) return1; while (n >= 7) { res *= 3; n -= 3; } if (n == 6) res *= 9; if (n == 5) res *= 6; if (n == 4) res *= 4; return res; }
intcuttingRope(int n){ int res = 1; if (n == 3) return2; if (n == 2) return1; while (n >= 7) { res *= 3; n -= 3; } if (n == 6) res *= 9; if (n == 5) res *= 6; if (n == 4) res *= 4; return res; }
classSolution { public: intcuttingRope(int n){ if (n <= 3) return1 * (n - 1); longlong res = 1; if (n % 3 == 1) res = 4, n -= 4; elseif (n % 3 == 2) res = 2, n -= 2; while (n) res *= 3, n -= 3, res %= 1000000007; return res; } };
思路二:
res仅用int,把res * 3可能溢出int,那就res 加3次,用加法代替乘法即可
核心代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
intcuttingRope(int n){ if (n <= 3) return1 * (n - 1); int res = 1; if (n % 3 == 1) res = 4, n -= 4; elseif (n % 3 == 2) res = 2, n -= 2; while (n) { // 加法代替乘法 int temp = res; res *= 2; res %= 1000000007; res += temp; res %= 1000000007; n -= 3; } return res; }
classSolution { public: ListNode* deleteNode(ListNode* head, int val){ auto dummy = newListNode(-1); dummy->next = head; auto i = head; for (; i; i = i->next) { if (i->val == val) break; } // 如果i是最后一个点,那就重新遍历,删除最后一个点 if (!i->next) { i = dummy->next; for (; i->next && i->next->next; i = i->next); i->next = nullptr; return dummy->next; }
classSolution { public: ListNode* deleteNode(ListNode* head, int val){ auto dummy = newListNode(-1); dummy->next = head; auto i = head; for (; i; i = i->next) { if (i->val == val) break; } // 如果i是最后一个点,那就重新遍历,删除最后一个点 if (!i->next) { i = dummy->next; for (; i->next && i->next->next; i = i->next); i->next = nullptr; return dummy->next; }
classSolution { public: ListNode* deleteNode(ListNode* head, int val){ auto dummy = newListNode(-1); dummy->next = head; auto i = head; for (; i; i = i->next) { if (i->val == val) break; } if (!i->next) { i = dummy->next; for (; i->next->next; i = i->next); i->next = nullptr; return dummy->next; }
classSolution { public: ListNode* deleteNode(ListNode* head, int val){ auto dummy = newListNode(-1); dummy->next = head; auto i = head; int res = 0; for (; i; i = i->next) { if (i->val == val) break; res++; }
i = dummy; while (res--) { i = i->next; } i->next = i->next->next; return dummy->next; } };
classSolution { public: unordered_map<int, int> hash; ListNode* deleteDuplication(ListNode* head){ auto dummy = newListNode(-1); dummy->next = head; auto p = dummy; int k = 0; for (auto i = head; i; i = i->next) { k++; hash[i->val]++; } int s = 0; for (auto i = head; i; i = i->next) { if (hash[i->val] == 1) { p->next = i; p = p->next; } else s++; } if (p->next && p->next->next && p->next->val == p->next->next->val) p->next = nullptr;
if (s == k) p->next = nullptr;
return dummy->next; } };
intmain(){ Solution solution; // 这里是自己构造一个链表,用来测试样例 int n; auto dummy = newListNode(-1); auto p = dummy; while (cin >> n, n != -1) { p->next = newListNode(n); p = p->next; }
cout << "原链表:" << endl; for (auto i = dummy->next; i; i = i->next) { cout << i->val << ' '; } cout << endl;
cout << "删除节点后的链表:" << endl; auto head = solution.deleteDuplication(dummy->next); for (auto i = head; i; i = i->next) { cout << i->val << ' '; } cout << endl;
classSolution { public: vector<int> spiralOrder(vector<vector<int>>& matrix){ if (matrix.size() == 0) return {}; if (matrix.size() == 1) return matrix[0]; int n = matrix.size(), m = matrix[0].size(); vector<vector<int>> f(n + 1, vector<int>(m + 1)); vector<int> res; int di[] = {0, 1, 0, -1}, dj[] = {1, 0, -1, 0}; int r = 0; for (int k = 0, i = 0, j = 0; k < n * m; k++) { res.push_back(matrix[i][j]); f[i][j] = 1; int a = i + di[r], b = j + dj[r]; if (a >= 0 && a < n && b >= 0 && b < m && f[a][b] == 0) { i = a, j = b; } else { r = (r + 1) % 4; i = i + di[r], j = j + dj[r]; } } return res; } };
/** * Your MinStack object will be instantiated and called as such: * MinStack* obj = new MinStack(); * obj->push(x); * obj->pop(); * int param_3 = obj->top(); * int param_4 = obj->min(); */
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode(int x) : val(x), left(NULL), right(NULL) {} * }; */ classSolution { public: vector<vector<int>> levelOrder(TreeNode* root) { vector<vector<int>> res; if (!root) return res; queue<TreeNode*> q; q.push(root); q.push(NULL);// root层的标识符 vector<int> level; while (q.size()) { auto t = q.front(); q.pop();
if (!t) { if (level.empty()) break; res.push_back(level); level.clear(); q.push(NULL); continue; } level.push_back(t->val); if (t->left) q.push(t->left); if (t->right) q.push(t->right); }
booldfs(int l, int r){ if (l >= r) returntrue; int root = pos[r]; int k = l; for (; k < r && pos[k] <= root; k++); int tempR = k - 1; for (; k < r; k++) { if (pos[k] > root) continue; returnfalse; } returndfs(l, tempR) && dfs(tempR + 1, r - 1); } };
vector<vector<int>> pathSum(TreeNode* root, int target) { int u = 0; tar = target; vector<int> res; dfs(root, u, res); return ans;kj }
voiddfs(TreeNode* &root, int u, vector<int> res){ if (!root) return; res.push_back(root->val); u += root->val; if (u == tar && !root->left && !root->right) { ans.push_back(res); return; } dfs(root->left, u, res); dfs(root->right, u, res); } };
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode(int x) : val(x), left(NULL), right(NULL) {} * }; */ classCodec { public:
// Encodes a tree to a single string. string serialize(TreeNode* root){ if (!root) return""; queue<TreeNode*> q; q.push(root); string ans; while (q.size()) { auto t = q.front(); q.pop(); // 空格作为分隔符,'#'表示空指针 if (!t) ans += '#'; else { ans += to_string(t->val); q.push(t->left); q.push(t->right); } ans += ' '; } // cout << ans << endl; return ans; } vector<string> str; // Decodes your encoded data to tree. TreeNode* deserialize(string data){ if (data.empty()) returnnullptr; str = split(data, ' ');
queue<TreeNode*> q; TreeNode* root = newTreeNode(stoi(str[0])); q.push(root); int i = 1; while (!q.empty()) { TreeNode* front = q.front(); q.pop(); if (str[i] != "#") { front->left = newTreeNode(stoi(str[i])); q.push(front->left); } ++i; if (str[i] != "#") { front->right = newTreeNode(stoi(str[i])); q.push(front->right); } ++i; } return root; }
vector<string> split(string data, char sp){ vector<string> ans; for (int i = 0; i < data.size(); i++) { for (int j = i + 1; j < data.size(); j++) { if (data[j] == sp) { ans.push_back(data.substr(i, j - i)); i = j + 1; } } } return ans; } };
// Your Codec object will be instantiated and called as such: // Codec codec; // codec.deserialize(codec.serialize(root));
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode(int x) : val(x), left(NULL), right(NULL) {} * }; */ classCodec { public:
// Encodes a tree to a single string. string serialize(TreeNode* root){ string res; dfs_s(root, res); return res; }
voiddfs_s(TreeNode* root, string &res){ // 构造前序遍历 if (!root) { res += "null "; return; } res += to_string(root->val); res += " "; dfs_s(root->left, res); dfs_s(root->right, res); return; }
// Decodes your encoded data to tree. TreeNode* deserialize(string data){ int u = 0; returndfs_d(data, u); }
TreeNode* dfs_d(string data, int &u){ if (u == data.size()) returnNULL;
int k = u; // 记录当前这个数是几位数 while (data[k] != ' ') k++;
// 如果当前字符串是“null”,则回到下一个数字的首部,表示这次构造的是一个null节点,并没孩子节点,所以跳过后面的递归 if (data[u] == 'n') { u = k + 1; returnNULL; }
int val = 0; // val存的是当前的数字 if (data[u] == '-') { // 如果数字是负的 for (int i = u + 1; i < k; i++) { val = val * 10 + data[i] - '0'; } val = -val; } else { // 如果是数字是正的 for (int i = u; i < k; i++) { val = val * 10 + data[i] - '0'; } }
/** * Your MedianFinder object will be instantiated and called as such: * MedianFinder* obj = new MedianFinder(); * obj->addNum(num); * double param_2 = obj->findMedian(); */
classSolution { public: intmaxSubArray(vector<int>& nums){ // 此时s是以前一个数结尾的子数组中,和最大的是多少 int res = INT_MIN, s = 0; for (int x : nums) { if (s < 0) s = 0; // 这里s指的是,以当前数结尾的,子数组的和的最大值 s += x; res = max(res, s); } return res; } };
classSolution { public: intcountDigitOne(int n){ if (n == 0) return0; vector<int> num; int ans = 0;
// 把每一位取出来,例如123,放进数组就是[3, 2, 1] while (n) { num.push_back(n % 10); n /= 10; }
// 从最高位开始,枚举每一位 for (int i = num.size() - 1; i >= 0; i--) { // left指的是枚举的那一位前面的数,例如枚举的是abcdef中的c,那么left就是ab;,那么right就是def,如果def是三位,t就是10<sup>3 int left = 0, right = 0, t = 1;
for (int j = num.size() - 1; j > i; j--) { left = left * 10 + num[j]; }
for (int j = i - 1; j >= 0; j--) { right = right * 10 + num[j]; t *= 10; }
// 首先将情况①加进去 ans += left * t; // 加入情况②的(2) if (num[i] == 1) ans += right + 1; // 加入情况②的(3) if (num[i] > 1) ans += t; } return ans; } };
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode(int x) : val(x), left(NULL), right(NULL) {} * }; */ classSolution { public: bool ans = true; boolisBalanced(TreeNode* root){ if (!root) return ans; dfs(root); return ans; }
intdfs(TreeNode* root){ if (!root) return0; int left = dfs(root->left), right = dfs(root->right); if (abs(left - right) > 1) { ans = false; return0; } returnmax(left, right) + 1; } };