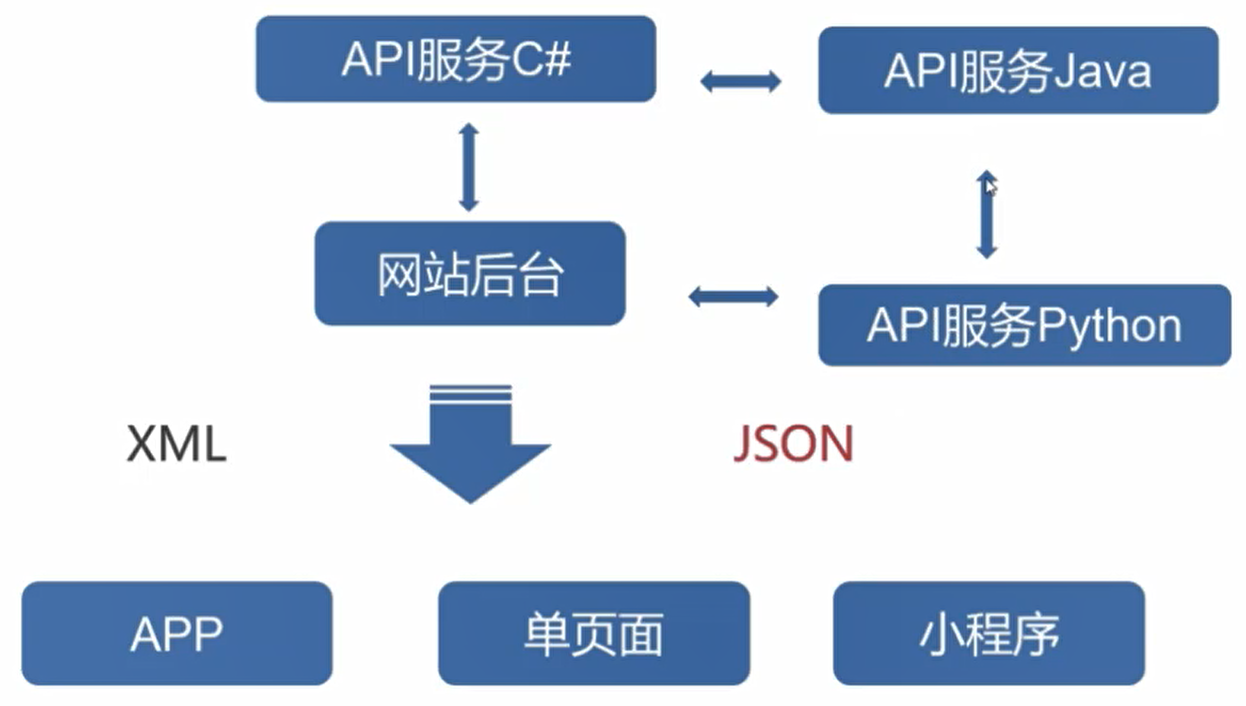
Python能做什么?
爬虫
大数据与数据分析 Spark
自动化运维与自动化测试
Web开发:Flask、Django
机器学习:Tensor Flow
胶水语言:混合其他如C++、Java等来编程。能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起
基本数据类型 查看数据类型 特殊:
‘/‘ 除法会自动转换为浮点数
‘//‘ 是整除
查看ascii码 查看变量在内存里的地址 转字符串 python不能字符串 + 数字,所以数字要先转成字符串
数字 整数 int:
bin( ) 转换为二进制
int( ) 转换为十进制
hex( ) 转换为十六进制
oct( ) 转换为八进制
浮点数 float:
默认都是双精度
布尔类型 bool:
只要非0即为真
1 2 3 4 bool (1.1 )bool (-1.1 )bool ('abc' )bool ([1 ,2 ,3 ])
空值会被认为是假
1 2 3 4 bool ('' )bool ([])bool ({})bool (None )
复数 complex:
用小写字母j表示,例如 a = 1 + 36j
序列 序列是有序的
字符串 str 字符串定义:
单引号,双引号:单行字符串
三引号:多行字符串
原始字符串:
字符串前面加一个 r ,那么它就不是一个普通字符串了,而是一个原始字符串(忽略转义)
1 2 3 4 5 6 7 8 a = '12\n456' print (a)b = r'12\n456' print (b)
拼接字符串:
1 2 3 4 a = "123" b = "456" c = a + b print (c)
字符串乘法:
1 2 3 a = "123" a *= 3 print (a)
字符串元素的访问:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 a = "0123456789" print (a[5 ]) print (a[-1 ]) print (a[0 :5 ]) print (a[0 :-1 ]) print (a[3 :]) print (a[-3 :]) print (a[:5 ]) print (a[:-3 ])
列表 list 列表中的元素不一定要是同类型的:
1 2 a = [1 , 2 , "哈哈" ] print (type (a))
列表中还可以嵌套列表:
1 2 a = [[1 , 2 , 3 ], ["123" , 0 ]] print (type (a))
列表元素的访问:
下标访问和字符串的访问一样,可以用下标单个访问,也可以用[0 : 2]范围访问
用单个下标访问,得到的是元素本身的类型
用 : 范围访问,得到的仍然是一个列表
1 2 3 4 5 a = [1 , 2 , 3 , "数字" ] print (type (a[0 ])) print (type (a[-1 ])) print (type (a[0 :])) print ((a[0 :]))
列表运算:
支持列表相加和列表乘以常数
1 2 3 4 5 6 a = [1 , 2 , 3 ]; b = [4 , 5 , 6 ]; c = a + b; print (c) b *= 3 ; print (b)
元组 tuple 元组中的元素不一定要是同类型的:
1 2 a = (1 , 2 , "345" ) print (type (a))
下标访问和字符串的访问一样,和列表也一样,支持单个元素下标访问,也支持范围访问
支持元组相加
支持元组乘以常数
定义只有一个元素的元组:
编译器规定,如果只有一个元素,不会吧( )识别成元组,而是识别成数学运算的( )去计算
1 2 3 4 a = ("hello" ) b = (1 ) print (type (a)) print (type (b))
定义只有一个元素的元组就在元素后面再加一个逗号即可:
1 2 3 4 a = ("hello" ,) b = (1 ,) print (type (a)) print (type (b))
定义空的元组:直接空括号即可
序列的共同特点 str,list,tuple
集合 集合 set set 是无序的,不支持下标索引,不支持切片:
1 2 3 a = {1 , 2 , 3 , 4 , 5 , 6 } print (type (a))
集合元素不重复:
1 2 a = {1 , 1 , 2 , 2 , 3 , 4 , 5 , 6 } print (a)
查看集合长度: len()
1 2 a = {1 , 1 , 2 , 2 , 3 , 4 , 5 , 6 } print (len (a))
支持in 和 not in:
1 2 3 a = {1 , 1 , 2 , 2 , 3 , 4 , 5 , 6 } print (1 in a)print (1 not in a)
支持max 和 min:
1 2 3 a = {1 , 1 , 2 , 2 , 3 , 4 , 5 , 6 } print (max (a))print (min (a))
支持求集合差集:
1 2 3 4 a = {1 , 2 , 3 , 4 , 5 , 6 } b = {3 , 4 } c = a - b print (c)
支持求交集:
1 2 3 4 a = {1 , 2 , 3 , 4 , 5 , 6 } b = {3 , 4 } c = a & b print (c)
支持求并集:
1 2 3 4 a = {1 , 2 , 3 , 4 , 5 , 6 } b = {3 , 4 , 7 } c = a | b print (c)
定义一个空的集合:
1 2 3 a = set () print (type (a)) print (len (a))
字典 dict 空的字典直接 a = {}即可
字典dict也是无序的
字典有key和value,通过key访问value
定义方式:
1 a = {key1:value1, key2:value2....}
1 2 a = {1 :1 , 2 :2 , 3 :3 } print (type (a))
例如:一个按键对应一个技能
1 2 a = {'Q' :'新月打击' , 'W' :'苍白之瀑' , 'E' :'月之降临' , 'R' :'月神冲刺' } print (a['Q' ])
字典不能有重复的key :
后插入的会覆盖前面插入的
1 2 a = {'Q' :'新月打击' , 'Q' :'苍白之瀑' , 'E' :'月之降临' , 'R' :'月神冲刺' } print (a)
value取值:
可以取python中任意的类型
key取值:
必须是不可变的类型,int,str,tuple
变量与运算符 变量 变量类型不固定:
1 2 3 4 a = 1 a = '1' a = (1 , 2 , 3 ) a = {1 , 2 , 3 }
最好不要用系统的函数名当作变量名,可以是可以,但是之后再用这个函数的时候会报错:
1 2 3 4 5 6 7 type = 1 print (type (1 ))// 报错 Traceback (most recent call last): File "D:/computer/coding/python/demo.py" , line 2 , in <module> print (type (1 )) TypeError: 'int' object is not callable
值类型 int,str,tuple 不可变的
1 2 3 4 a = 1 b = a a = 3 print (b)
实验1:a + ‘python’ 以后其实变成了一个新的字符串,内存地址变了
1 2 3 4 5 a = 'hello' print (id (a)) a = a + 'python' print (id (a)) print (a)
实验2:改内部就会报错
1 2 3 4 5 6 7 a = 'hello' a[0 ] = 'o' // 报错 Traceback (most recent call last): File "D:/computer/coding/python/demo.py" , line 2 , in <module> a[0 ] = 'o' TypeError: 'str' object does not support item assignment
实验3:tuple内部也是不能变的
1 2 3 4 5 6 7 8 9 a = (1 , 2 , 3 ) a[0 ] = '1' // 报错 Traceback (most recent call last): File "D:/computer/coding/python/demo.py" , line 2 , in <module> a[0 ] = '1' TypeError: 'tuple' object does not support item assignment Process finished with exit code 1
引用类型 list,set,dict 可变的
1 2 3 4 5 a = [1 , 2 , 3 , 4 , 5 ] b = a a[0 ] = '1' print (a) print (b)
实验1:list改变以后,地址不变,仍然是同一个list
1 2 3 4 a = [1 , 2 , 3 ] print (id (a)) a += [4 , 5 , 6 ] print (id (a))
实验2:对比list和tuple
1 2 3 4 5 6 7 a = [1 , 2 , 3 ] a.append(4 ) print (a)c = (1 , 2 , 3 ) print (c)
实验3:tuple不可变,但是内部的列表可以变
1 2 3 a = (1 , 2 , 4 , [1 , 2 , 3 ]) a[3 ][2 ] = 'q' print (a[3 ][2 ])
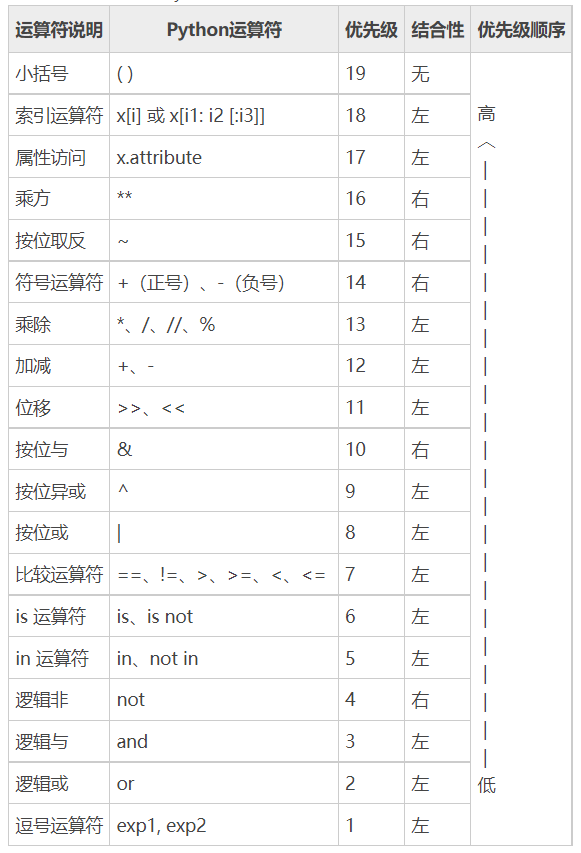
运算符 运算符优先级 算数运算符 整除:5 // 2 = 2
除法:5 / 2 = 2.5
次方:5 ** 2 = 25,5 ** 3 = 125
逻辑运算符 与:and
或:or
非:not
int,float:值为0时,被认为是False,非0被认为是True
字符串:空串被认为是False,非空字符串是True
list,set,tuple,dict:空被认为是False,非空是True
成员运算符 in:元素是否在后面的组中
1 2 print (1 in [1 , 2 , 3 ]) print ('q' in 'qwer' )
not in:元素是否不在后面的组中
注意:字典的成员运算,看的是key在不在dict中
身份运算符 is:比较两个变量的内存地址是否相等,==是比较两个变量的值是否相等
实验1:值比较
1 2 3 print (1 is 1.0 ) print (1 is 1 ) print (1 == 1.0 )
实验2:list比较,因为集合是无序的,1,2,3还是2,1,3不影响值相等
1 2 3 4 5 6 a = {1 , 2 , 3 } b = {2 , 1 , 3 } print (id (a)) print (a == b) print (id (b)) print (a is b)
实验3:tuple比较,因为元组是有序的,1,2,3还是2,1,3值不一样
1 2 3 4 5 6 a = (1 , 2 , 3 ) b = (2 , 1 , 3 ) print (id (a)) print (a == b) print (id (b)) print (a is b)
is not:比较两个变量的内存地址是否不相等
值,身份,类型 对象的三个特征:值,身份,类型
Python中一切都是对象,int,”str”,(),{},[]
值比较:a == b
身份比较:a is b
类型比较:isinstance
1 2 3 4 5 6 7 a = 1 print (type (a) == int ) b = "hello" print (isinstance (b, str )) print (isinstance (b, int )) print (isinstance (b, (int , str , float )))
位运算符 &:按位与
|:按位或
^:按位异或
~:按位取反
<<:左移
>>:右移
分支、循环、条件与枚举 接受控制台输入:input()
pass:占位符
if , else , elif 1 2 3 4 5 6 7 8 9 10 11 12 13 account = 'guolin' password = '123456' print ('please input account' )user_account = input () print ('please input password' )user_password = input () if account == user_account and password == user_password: print ('success' ) else : print ('fail' )
while,else 1 2 3 4 5 6 a = 0 while a <= 10 : a += 1 print (a) else : print ('EOF' )
for,else 主要是用来遍历/循环 序列,集合或者字典
print(y, end = '')控制每个输出的末尾是什么,如果不指定end,默认是换行
1 2 3 4 5 6 7 a = [['a' , 'b' , 'c' ], (1 , 2 , 3 )] for x in a: for y in x: print (y, end = ' ' ) else : print ('for-else' )
range 1 2 3 for x in range (0 , 10 , 2 ): print (x)
1 2 3 for x in range (10 , 0 , -2 ): print (x)
1 2 3 4 5 6 7 8 a = [1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ] for i in range (0 , len (a), 2 ): print (a[i], end = ' | ' ) print ()b = a[0 :len (a):2 ] print (b)
break和continue 1 2 3 4 5 6 7 8 9 10 a = (1 , 2 ,3 ) for x in a: if x == 2 : break print (x) for x in a: if x == 2 : continue print (x)
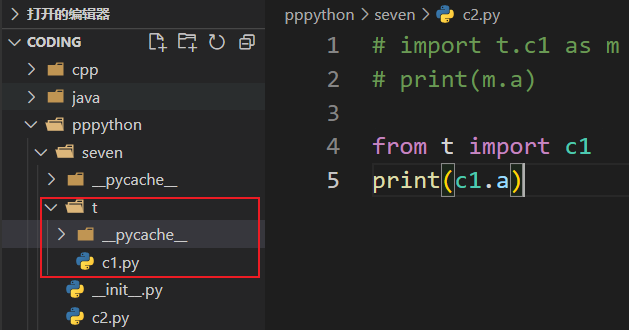
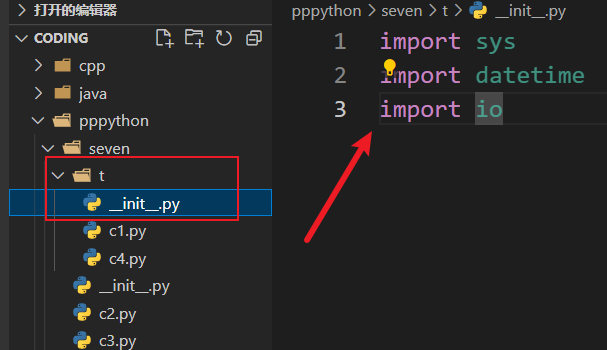
包、模块、类 定义 一个文件夹就是一个包,并且这个文件夹下有__init__.py文件,如果没有__init__.py,python会认为这是一个普通的文件夹,__init__.py文件也是一个模块,并且这个模块的模块名就是包名
模块就是 .py 文件
模块里面的class就是类
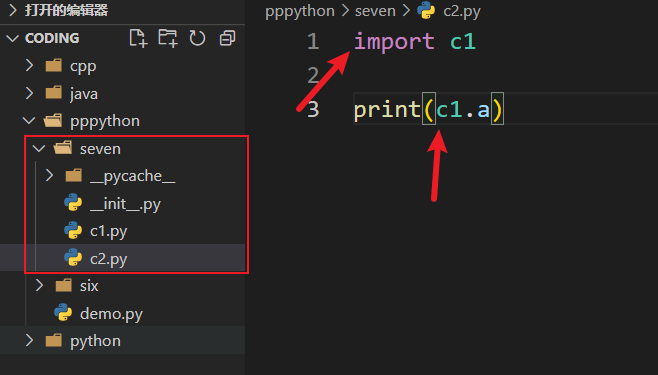
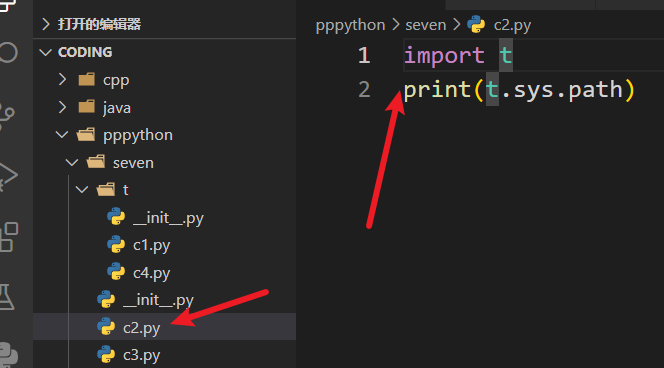
import导包 同级别的模块导入
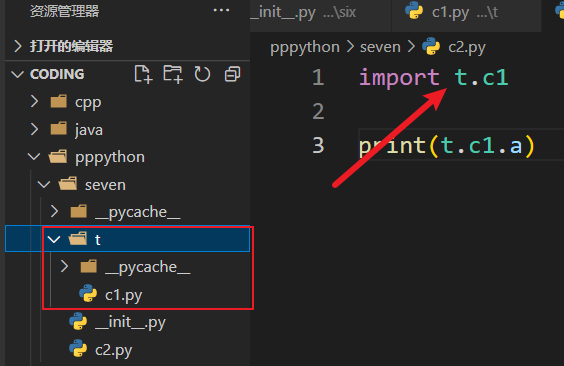
从子包里面的模块导入
as别名 1 2 3 import t.c1 as mprint (m.a)
编译器自动生成的字节码文件
直接导入具体的变量 from module import a
1 2 3 4 5 from t.c1 import aprint (a)
这样也可以
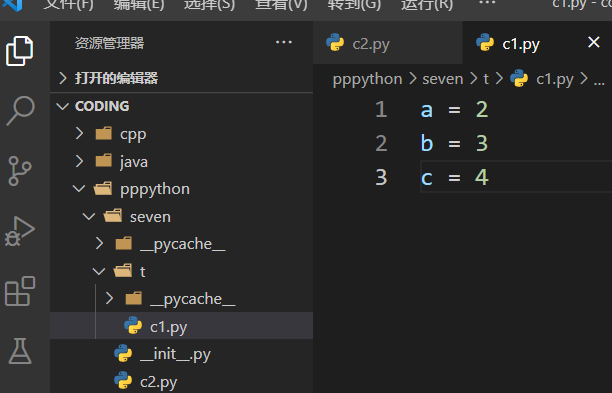
1 2 from t import c1print (c1.a)
使用*一次性导入所有变量 c1:
c2:
1 2 3 4 from t.c1 import *print (a) print (b) print (c)
__all__列表,指定*导入的变量 c1:
1 2 3 4 5 __all__ = [a, c] a = 2 b = 3 c = 4
c2:
1 2 3 4 5 from t.c1 import *print (a) print (c) print (b)
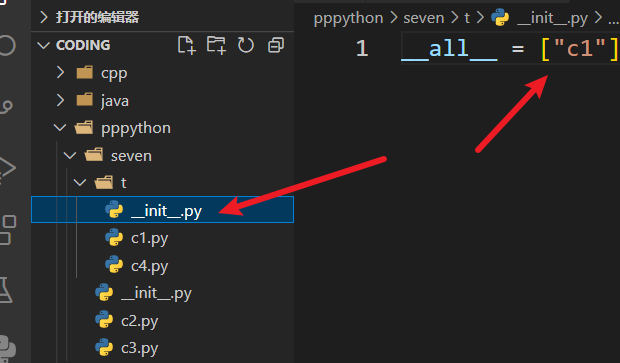
在init文件中使用all:
可以指定 * 导入的时候,导入哪些包
例如:
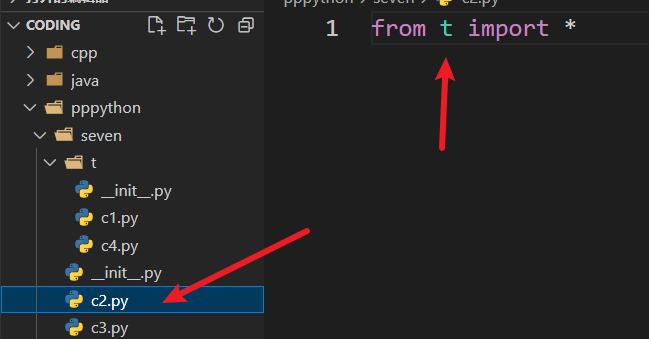
all只指定了c1,没有指定c4:
那么用 * 一次性导入的时候,只会导入c1,也就是init中的all列表中的模块
导入换行 不换行:
1 2 3 4 from t.c1 import a, b, cprint (a) print (b) print (c)
用\换行:
1 2 from t.c1 import a, b, \c
用()换行:
1 2 from t.c1 import (a, b, c)
init文件 导入包的时候,python会自动运行init文件
init文件:
1 2 a = 'This is __init__.py file' print (a)
其他文件导包的时候:
输出结果:
1 This is __init__.py file
应用: 批量导入
可以在init文件里面统一导包,然后再在其他包里面导入init所在的包即可
注意事项 包和模块是不会重复导入的
避免循环导入
p1文件:
1 2 3 from p2 import p2p1 = 1 print (p2)
p2文件:
1 2 from p1 import p1p2 = 2
python导入模块的时候,会自动执行模块里面的所有代码
函数 python默认递归深度是995(不同计算机和系统默认深度不一样)
下列语句可以自定义最大递归深度
1 2 import syssys.setrecursionlimit(1000000 )
函数返回值 函数如果没有返回值就会返回None
1 2 3 4 5 6 7 8 9 10 def add (x, y ): return x + y def print_code (code ): print (code) a = add(1 , 2 ) b = print_code(a) print (a, b)
序列解包 自动解包,指定有意义的变量名称,利于维护
1 2 3 4 5 6 7 8 9 10 11 12 13 def damage (skill1, skill2 ): damage1 = skill1 * 3 damage2 = skill2 * 2 + 10 return damage1, damage2 damages = damage(3 , 6 ) print (type (damages)) print (damages) skill1_damage, skill2_damage = damage(3 , 6 ) print (skill1_damage, skill2_damage)
例子:
1 2 3 4 5 6 7 a, b, c = 1 , 2 , 3 d = 1 , 2 , 3 print (type (d))x, y, z = d
参数 必须参数 1 2 3 4 5 def add (x, y ): return x + y c = add(3 , 2 )
关键字参数 1 2 3 4 5 def add (x, y ): return x + y d = add(y = 2 , x = 3 )
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict
1 2 3 4 5 6 def person (name, age, **kw ): print ('name:' , name, 'age:' , age, 'other:' , kw) person('Michael' , 30 ) person('Bob' , 35 , city='Beijing' ) person('Adam' , 45 , gender='M' , job='Engineer' )
关键字参数有什么用?它可以扩展函数的功能。比如,在person函数里,我们保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,我们也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
和可变参数类似,也可以先组装出一个dict,然后,把该dict转换为关键字参数传进去:
1 2 3 4 5 def person (name, age, **kw ): print ('name:' , name, 'age:' , age, 'other:' , kw) extra = {'city' : 'Beijing' , 'job' : 'Engineer' } person('Jack' , 24 , **extra)
默认参数 1 2 3 4 5 def add (x, y=5 ): return x + y c = add(3 ) print (c)
可变参数 在Python函数中,还可以定义可变参数。顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
我们以数学题为例子,给定一组数字a,b,c……,请计算a2 + b2 + c2
要定义出这个函数,我们必须确定输入的参数。由于参数个数不确定,我们首先想到可以把a,b,c……作为一个list或tuple传进来,这样,函数可以定义如下:
1 2 3 4 5 def calc (numbers ): sum = 0 for n in numbers: sum = sum + n * n return sum
但是调用的时候,需要先组装出一个list或tuple:
1 2 3 4 5 6 7 8 9 def calc (numbers ): sum = 0 for n in numbers: sum = sum + n * n return sum print (calc([1 , 2 , 3 ])) print (calc((1 , 3 , 5 , 7 )))
如果利用可变参数,调用函数的方式可以简化成这样:
1 2 3 4 5 6 7 8 9 def calc (*numbers ): sum = 0 for n in numbers: sum = sum + n * n return sum print (calc(1 , 2 , 3 )) print (calc(1 , 3 , 5 , 7 ))
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数:
1 2 3 4 5 6 7 def calc (*numbers ): sum = 0 for n in numbers: sum = sum + n * n return sum print (calc())
如果已经有一个list或者tuple,要调用一个可变参数怎么办?可以这样做:
1 2 3 4 5 6 7 8 def calc (*numbers ): sum = 0 for n in numbers: sum = sum + n * n return sum nums = [1 , 2 , 3 ] print (calc(*nums))
global关键字 global 标志实际上是为了提示 python 解释器,表明被其修饰的变量是全局变量
1 2 3 4 5 6 7 8 9 10 11 12 origin = 0 def go (step ): global origin new_pos = origin + step origin = new_pos return new_pos print (go(2 )) print (go(3 )) print (go(6 ))
报错的例子:
1 2 3 4 5 6 7 8 9 10 11 12 origin = 0 def go (step ): new_pos = origin + step origin = new_pos return new_pos print (go(2 ))print (go(3 ))print (go(6 ))
nonlocal关键字 强制申明一个变量不是局部变量,要从外部引用
闭包的方式解决:
pos和go函数一起形成了闭包,闭包可以使pos记忆上一次调用的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 origin = 0 def factory (pos ): def go (step ): nonlocal pos new_pos = pos + step pos = new_pos return new_pos return go tourist = factory(origin) print (tourist(2 )) print (tourist(3 )) print (tourist(6 ))
面向对象 变量直接定义在模块里面,就是全局变量 ,函数中可以直接使用
变量定义在类下面,被称为数据成员
函数里面的是局部变量
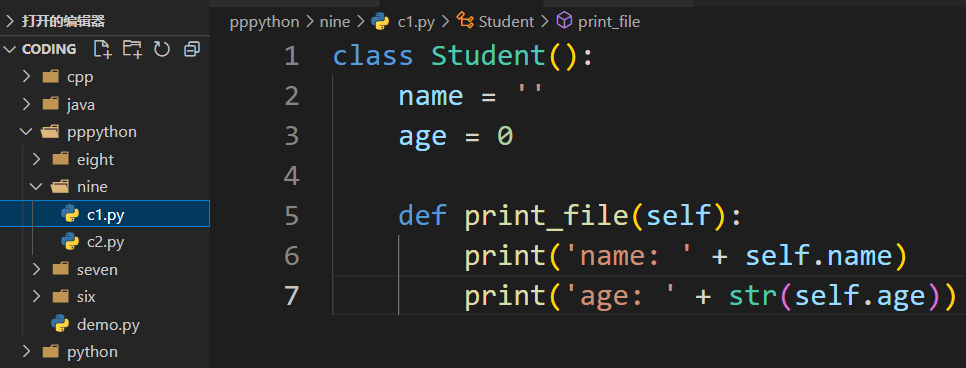
类的定义和方法调用 1 2 3 4 5 6 7 8 9 10 11 12 class Student (): name = '' age = 0 def print_file (self ): print ('name: ' + self.name) print ('age: ' + str (self.age)) student = Student() student.print_file()
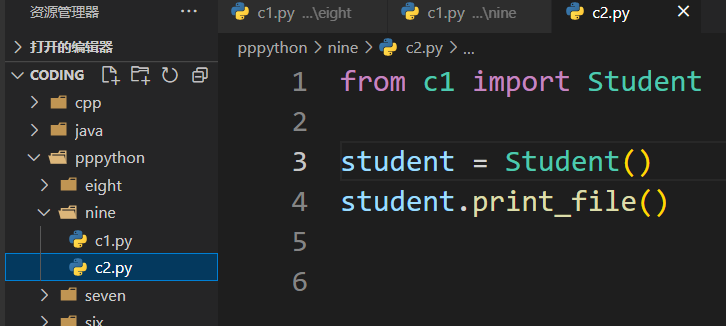
调用其他模块的类
构造函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Student (): name = '' age = 0 def __init__ (self ): print ('student' ) def do_homework (self ): print () student1 = Student() a = student1.__init__() print (a) print (type (a))
构造函数默认返回值是None,也可以显式的返回None
1 2 3 4 5 6 7 8 class Student (): name = '' age = 0 def __init__ (self ): print ('student' ) return None
但是和其他函数不同的是,构造函数不能返回除了None以外的其他值
1 2 3 4 5 6 7 8 class Student (): name = '' age = 0 def __init__ (self ): print ('student' ) return 'student'
报错:
1 2 3 4 Traceback (most recent call last): File "c1.py" , line 14 , in <module> student1 = Student() TypeError: __init__() should return None , not 'str'
类变量和实例变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Student (): name = '' age = 0 def __init__ (self, name, age ): self.name = name self.age = age def do_homework (self ): print ('do_homework' ) student1 = Student('小明' , 18 ) student2 = Student('小红' , 19 ) print (student1.name)print (student1.age)print (student2.name)print (student2.age)
实例变量并不能改变类变量的值,类变量只和类相关,不受对象的影响:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Student (): name = 'guolin' age = 0 def __init__ (self, name, age ): self.name = name self.age = age def do_homework (self ): print ('do_homework' ) student1 = Student('小明' , 18 ) student2 = Student('小红' , 19 ) print (student1.name) print (student2.name) print (Student.name)
没有定义类变量,一样可以有实例变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Student (): def __init__ (self, name, age ): self.name = name self.age = age def do_homework (self ): print ('do_homework' ) student1 = Student('小明' , 18 ) student2 = Student('小红' , 19 ) print (student1.name) print (student2.name)
dict变量 python中每个实例中自带了一个__dict__字典,可以通过实例名.__dict__的方式查看这个实例的实例变量有哪些
1 2 3 4 5 6 7 8 9 10 11 class Student (): def __init__ (self, name, age ): self.name = name self.age = age def do_homework (self ): print ('do_homework' ) student1 = Student('小明' , 18 ) print (student1.__dict__)
python机制:在class外部调用一个变量,如果对象里面,没有找到指定的实例变量,就会自动去类里面找,如果还没找到,会去父类里面找,所以下面的student1没有实例变量,python自动去类变量里面找,所以student1.name和Student.name输出的值一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Student (): name = 'guolin' age = 0 def __init__ (self, name, age ): name = name age = age def do_homework (self ): print ('do_homework' ) student1 = Student('小明' , 18 ) print (student1.__dict__) print (student1.name) print (Student.name)
类也可以用__dict__查看类的变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Student (): name = 'guolin' age = 0 def __init__ (self, name, age ): name = name age = age def do_homework (self ): print ('do_homework' ) student1 = Student('小明' , 18 ) print (student1.__dict__) print (Student.__dict__)
实例方法内部访问类变量 通过类名.类变量访问
通过self.__class__.类变量访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Student (): sum = 0 def __init__ (self, name, age ): self.name = name self.age = age print (Student.sum ) print (self.__class__.sum ) def do_homework (self ): print ('do_homework' ) student1 = Student('小明' , 18 )
类方法 装饰器:@classmethod
类可以调用类方法,对象也可以直接调用类方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Student (): sum = 0 def __init__ (self, name, age ): self.name = name self.age = age def do_homework (self ): print ('do_homework' ) @classmethod def plus_sum (cls ): cls.sum += 1 print (cls.sum ) student1 = Student('小明' , 18 ) Student.plus_sum() student1 = Student('小红' , 18 ) Student.plus_sum() student1 = Student('小军' , 18 ) Student.plus_sum()
静态方法 @staticmethod
对象和类都可以直接调用静态方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Student (): sum = 0 def __init__ (self, name, age ): self.name = name self.age = age def do_homework (self ): print ('do_homework' ) @classmethod def plus_sum (cls ): cls.sum += 1 print (cls.sum ) @staticmethod def add (x, y ): print ('This is a staticmethod' ) student1 = Student('小明' , 18 ) student1.add(1 , 2 ) Student.add(1 , 2 )
可见性 实例方法内部可以调用其他方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Student (): sum = 0 def __init__ (self, name, age, score ): self.name = name self.age = age self.score = score def do_homework (self ): self.do_english_homework() print ('do_homework' ) def do_english_homework (self ): print ('do_english_homework' ) @classmethod def plus_sum (cls ): cls.sum += 1 print (cls.sum ) @staticmethod def add (x, y ): print ('This is a staticmethod' ) student1 = Student('小明' , 18 ) student1.do_homework()
public,private:
在方法或者变量面前加双下划线,python就会认为这个变量是私有的,否则就是公开的
python的私有变量保护机制其实就是把变量名换了,例如本来是__score,python会改成_Student__score
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Student (): sum = 0 def __init__ (self, name, age ): self.name = name self.age = age self.__score = 0 def marking (self, score ): if score < 0 : return '不能打负分' self.__score = score print (self.name + '分数为: ' + str (self.__score)) def do_homework (self ): self.do_english_homework() print ('do_homework' ) def do_english_homework (self ): print ('do_english_homework' ) @classmethod def plus_sum (cls ): cls.sum += 1 print (cls.sum ) @staticmethod def add (x, y ): print ('This is a staticmethod' ) student1 = Student('小明' , 18 ) result = student1.marking(-59 ) print (result)print (student1.__dict__) student1._Student__score = -1 print (student1._Student__score)
继承 Python 子类可以继承父类的类变量和实例变量,方法
调用父类的方法:super(Student, self).do_homework()
父类:
1 2 3 4 5 6 7 8 9 10 11 12 class Human (): sum = 0 def __init__ (self, name, age ): self.name = name self.age = age self.__class__.sum += 1 def get_name (self ): print (self.name) def do_homework (self ): print ('This is a parent method!' )
子类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from c1 import Humanclass Student (Human ): def __init__ (self, school, name, age ): self.school = school super (Student, self).__init__(name, age) def do_homework (self ): super (Student, self).do_homework() print ('do_homework' ) student1 = Student('人民路小学' , '石敢当' , 18 ) student1.do_homework() print (student1.name)print (student1.age)
对比Java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 public class test1 { public static void main(String[] args) { Student student = new Student("小明" , 18 , "人民路小学" ); System.out.println(student.getName()); System.out.println(student.getAge()); System.out.println(student.getSchool()); } } class Human { private String name; private int age; public Human() { } public Human(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } class Student extends Human { private String school; public Student() { } public Student(String school) { this.school = school; } public Student(String name, int age, String school) { super (name, age); this.school = school; } public String getSchool() { return school; } public void setSchool(String school) { this.school = school; } }
正则表达式 定义:正则表达式是一个特殊的字符序列,一个字符串是否与我们所设定这样的字符序列,相匹配
作用:快速检索文本、实现一些替换文本的操作
应用:
1.检查一串数字是否是电话号码
2.检测一个字符串是否符合email
3.把一个文本里指定的单词替换为另外一个单词
python内置函数 1 2 3 4 5 6 a = 'c|c++|c#|java|python' print (a.index('python' )) print (a.index('python' ) > -1 ) print ('python' in a)
findall方法 1 2 3 4 5 6 7 8 9 import rea = 'c|c++|c#|java|python' r = re.findall('python' , a) if len (r) > 0 : print ('字符串中包含python' ) print (r)
概括字符集
数字:\d == [0-9]
非数字:\D ==[^0-9]
数字+字母+下划线(单词字符):\w == [A-Za-z0-9_]
非数字+字母+下划线(非单词字符):\W == [^A-Za-z0-9_],[' ', '\n', '&', '\r', '\t']都是非单词字符
匹配任何不可见字符:\s == [ \f\n\r\t\v],包括空格、制表符、换页符等等
匹配任何可见字符(非空白字符):\S
匹配除换行符之外其他所有字符:.
匹配一个数字字符:
普通字符:’python’,元字符:’\d’
1 2 3 4 5 6 import rea = 'c0c++1c#3java5python' r = re.findall('\d' , a) print (r)
匹配一个非数字字符:
1 2 3 4 5 6 import rea = 'c0c++1c#3java5python' r = re.findall('\D' , a) print (r)
字符集:普通字符+元字符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import res = 'abc, acc, adc, aec, afc, ahc' r = re.findall('a[cf]c' , s) print (r) r = re.findall('a[^cfd]c' , s) print (r) r = re.findall('a[c-f]c' , s) print (r)
数量词 1 2 3 4 5 6 7 import res = 'python 1111java678php' r = re.findall('[a-z]{3,6}' , s) print (r)
贪婪与非贪婪 python的正则表达式数量词,默认是贪婪的,自动的匹配更多:
1 2 3 4 5 6 7 import res = 'python 1111java678php' r = re.findall('[a-z]{3,6}' , s) print (r)
非贪婪:
1 2 3 4 5 6 import res = 'python 1111java678php' r = re.findall('[a-z]{3,6}?' , s) print (r)
*号,+号,?号 *号前面的字符可以是任意次,包括0次
1 2 3 4 5 6 import res = 'pytho0python1pythonn2' r = re.findall('python*' , s) print (r)
+号前面的字符为1次到无限多次
1 2 3 4 5 6 import res = 'pytho0python1pythonn2' r = re.findall('python+' , s) print (r)
?号前面的字符为0次或1次,可以用来去重
1 2 3 4 5 6 import res = 'pytho0python1pythonn2' r = re.findall('python?' , s) print (r)
边界匹配 判断qq号是否为4-8位:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import reqq = '101' r = re.findall('\d{4,8}' , qq) print (r) qq = '100001' r = re.findall('\d{4,8}' , qq) print (r) qq = '100000001' r = re.findall('\d{4,8}' , qq) print (r) qq = '100000001' r = re.findall('^\d{4,8}$' , qq) print (r)
^与$的解释:
1 2 3 4 5 6 7 8 9 10 11 12 13 import reqq = '100000001' r = re.findall('000' , qq) print (r) r = re.findall('^000' , qq) print (r) r = re.findall('000$' , qq) print (r)
分组数量词 1 2 3 4 5 6 import rea = 'pythonpythonpythonpython' r = re.findall('(python){2}' , a) print (r)
匹配模式参数 第三个参数是匹配模式参数
re.I为忽略大小写
原本.是匹配除换行符之外其他所有字符,re.S可以让.匹配所有字符,包括换行符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import rea = 'PythonC#\nJavaPHP' r = re.findall('c#' , a) print (r) r = re.findall('c#' , a, re.I) print (r) r = re.findall('c#.{1}' , a, re.I) print (r) r = re.findall('c#.{1}' , a, re.I | re.S) print (r)
sub方法,替换 替换,默认把所有参数替换掉,第四个参数默认是0,替换所有
第四个参数的意思是,匹配到后,所能够替换的最大的次数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import rea = 'PythonC#JavaC#C#PHP' r = re.sub('C#' , 'GO' , a) print (r) r = re.sub('C#' , 'GO' , a, 1 ) print (r) r = re.sub('C#' , 'GO' , a, 2 ) print (r)
Python内置的的替换函数replace:
1 2 3 4 5 6 7 8 9 10 11 a = 'PythonC#JavaC#C#PHP' a.replace('C#' , 'GO' ) print (a) a = a.replace('C#' , 'GO' ) print (a)
把函数作为参数传入sub:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import rea = 'PythonC#JavaC#C#PHP' def convert (value ): print (type (value)) return '!!' + value.group() + '!!' r = re.sub('C#' , convert, a) print (r)
将小于6的数字变成0,大于等于6的改成9:
1 2 3 4 5 6 7 8 9 10 11 12 13 import res = 'A8Casd867328918' def convert (value ): matched = value.group() if int (matched) >= 6 : return '9' else : return '0' r = re.sub('\d' , convert, s) print (r)
match与search方法 1 2 3 4 5 6 7 8 9 10 11 import res = 'qwe1231DW123Q4GE2RW' r = re.match ('\d' , s) print (r)r1 = re.search('\d' , s) print (r1)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import res = '1231DW123Q4GE2RW' r = re.match ('\d' , s) print (r) print (r.group()) print (r.span()) r1 = re.search('\d' , s) print (r1) print (r.group()) print (r.span()) r2 = re.findall('\d' , s) print (r2)
group分组 1 2 3 4 5 6 7 8 9 10 11 12 import res = 'life is short, i use python' r = re.search('life (.*) python' , s) print (r.group(0 )) print (r.group(1 )) r = re.findall('life (.*) python' , s) print (r)
groups:
1 2 3 4 5 6 7 8 9 10 11 import res = 'life is short, i use python, i love python' r = re.search('life(.*)python(.*)python' , s) print (r.group(0 )) print (r.group(1 )) print (r.group(2 )) print (r.group(0 , 1 , 2 )) print (r.groups())
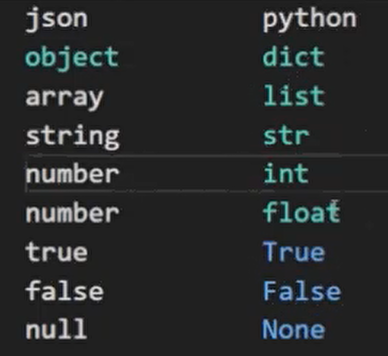
JSON JSON介绍 定义: JavaScript Object Notation(JavaScript对像标记)是一种轻量级的数据交换格式
载体: 字符串是JSON的表现形式,符合JSON格式的字符串叫做JSON字符串
优点: 易于阅读,易于解析,网络传输效率高,跨语言交换数据
XML长什么样:
JSON跨语言,数据交换:
Python中JSON的格式 JSON中字符串必须以双引号表示,JSON的每个key都是字符串,要加双引号
value如果是字符串也要加双引号,数字不用加,bool类型也不用加
1 2 json_str = '{"name":"qiyue", "age":18}' json_str = '[{"name":"qiyue", "age":18}, {"name":"qiyue", "age":18}]'
反序列化 将JSON转换为Python中的数据结构
loads方法 将json字符串转换为dict:
1 2 3 4 5 6 7 8 import jsonjson_str = '{"name":"qiyue", "age":18}' student = json.loads(json_str) print (type (student)) print (student)
将json数组转换为list,list里面每个元素是一个dict:
1 2 3 4 5 6 7 import jsonjson_str = '[{"name":"qiyue", "age":18}, {"name":"qiyue", "age":18}]' student = json.loads(json_str) print (type (student)) print (student)
序列化 将Python数据类型转换为JSON
dumps方法 1 2 3 4 5 6 7 8 9 10 import jsonstudent = [ {"name" :"qiyue" , "age" :18 , "flag" :False }, {"name" :"qiyue" , "age" :18 } ] json_str = json.dumps(student) print (type (json_str)) print (json_str)
JSON,JSON对象,JSON字符串 JSON是一种中间的数据类型,实现不同语言之间的快速转换
JSON有自己的数据类型,虽然它和JavaScript的数据类型有些相似
JSON对象和JSON字符串其实脱离语言来看,是一样的
枚举 枚举是一个类,所有的枚举都是Enum的子类
为什么要用枚举? 其他三种方式的缺陷:值可变,没有防止相同标签的功能
1 2 3 4 5 6 7 8 9 10 11 yellow = 1 green = 2 {'yellow' :1 , 'green' :2 } class TypeDiamond (): yellow = 1 green = 2
枚举的值不可变 1 2 3 4 5 6 7 8 9 10 11 from enum import Enumclass VIP (Enum ): YELLOW = 1 GREEN = 2 BLACK = 3 RED = 4 print (VIP.YELLOW)
枚举不允许相同标签 1 2 3 4 5 6 7 8 9 from enum import Enumclass VIP (Enum ): YELLOW = 1 YELLOW = 2 BLACK = 3 RED = 4 print (VIP.YELLOW)
相关操作 枚举类型,枚举的名字,枚举的值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from enum import Enumclass VIP (Enum ): YELLOW = 1 GREEN = 2 BLACK = 3 RED = 4 print (type (VIP.GREEN)) print (VIP.GREEN) print (type (VIP.GREEN.value)) print (VIP.GREEN.value) print (type (VIP.GREEN.name)) print (VIP.GREEN.name)
遍历枚举 1 2 3 4 5 6 7 8 9 10 from enum import Enumclass VIP (Enum ): YELLOW = 1 GREEN = 2 BLACK = 3 RED = 4 for v in VIP: print (v)
枚举间的比较 枚举类型之间不能做大小比较,但是可以做等值比较
枚举类型可以做身份比较
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from enum import Enumclass VIP (Enum ): YELLOW = 1 GREEN = 1 BLACK = 3 RED = 4 result = VIP.YELLOW == VIP.GREEN print (result) result = VIP.BLACK is VIP.BLACK print (result) result = VIP.YELLOW is VIP.GREEN print (result)
标签别名 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from enum import Enumclass VIP (Enum ): YELLOW = 1 YELLOW_ALIAD = 1 BLACK = 3 RED = 4 print (VIP.YELLOW_ALIAD) for v in VIP: print (v) for v in VIP.__members__: print (v)
类型转换 将数字转换为枚举类型
1 2 3 4 5 6 7 8 9 10 11 12 from enum import Enumclass VIP (Enum ): YELLOW = 1 GREEN = 1 BLACK = 3 RED = 4 a = 1 print (VIP(a)) print (type (VIP.BLACK)) print (isinstance (VIP.BLACK, VIP))
标签的值的类型 标签的值可以是其他类型,不一定要是数字
1 2 3 4 5 6 7 from enum import Enumclass VIP (Enum ): YELLOW = 1 GREEN = (1 , 2 , 3 ) BLACK = 'str' RED = {213 :1 }
强制指定标签的值为int 1 2 3 4 5 6 7 from enum import IntEnumclass VIP (IntEnum ): YELLOW = 1 GREEN = 2 BLACK = 3 RED = 4
限制标签的值不相同 枚举类的上面加装饰器@unique
1 2 3 4 5 6 7 8 from enum import IntEnum, unique@unique class VIP (IntEnum ): YELLOW = 1 GREEN = 1 BLACK = 3 RED = 4
枚举底层 枚举类型的实现是单例模式,不能对枚举类型实例化
一切皆对象 函数也是对象,函数可以赋值给一个变量
可以把函数作为另一个函数的参数,传递到另外的函数里
把一个函数当作另一个函数的返回值
1 2 3 4 def a (): pass print (type (a))
1 2 3 4 5 6 7 def curve_pre (): def curve (): print ('this is a function' ) return curve f = curve_pre() f()
闭包 保存了一个现场
由函数以及它在定义时候的外部的环境变量(不能是全局变量)所构成的整体,就是闭包
当闭包形成之后,这个函数在任何地方调用的时候,都不会受到重新赋值的影响,还是会用闭包时的环境变量
外部的环境变量的例子: 形成闭包
1 2 3 4 5 6 7 8 9 def curve_pre (): a = 25 def curve (x ): return a*x*x return curve a = 10 f = curve_pre() print (f(2 ))
全局变量的例子: 没有形成闭包
1 2 3 4 5 6 7 8 9 a = 25 def curve_pre (): def curve (x ): return a*x*x return curve a = 10 f = curve_pre() print (f(2 ))
局部变量的改变无法影响全局变量:
1 2 3 4 5 6 7 8 9 10 11 def f1 (): a = 10 def f2 (): a = 20 print (a) print (a) f2() print (a) f1()
没有形成闭包的例子:
1 2 3 4 5 6 7 8 9 10 11 12 def f1 (): a = 10 def f2 (): a = 20 return a return f2 f = f1() print (f) print (f.__closure__)
改成闭包:
1 2 3 4 5 6 7 8 9 10 11 def f1 (): a = 10 def f2 (): return a return f2 f = f1() print (f) print (f.__closure__)
global全局变量 1 2 3 4 5 6 7 8 9 10 11 12 origin = 0 def go (step ): global origin new_pos = origin + step origin = new_pos return new_pos print (go(2 )) print (go(3 )) print (go(6 ))
报错的例子:
1 2 3 4 5 6 7 8 9 10 11 12 origin = 0 def go (step ): new_pos = origin + step origin = new_pos return new_pos print (go(2 ))print (go(3 ))print (go(6 ))
nonlocal非局部变量 强制申明一个变量不是局部变量,要从外部引用
闭包的方式解决:
pos和go函数一起形成了闭包,闭包可以使pos记忆上一次调用的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 origin = 0 def factory (pos ): def go (step ): nonlocal pos new_pos = pos + step pos = new_pos return new_pos return go tourist = factory(origin) print (tourist(2 )) print (tourist(3 )) print (tourist(6 ))
lambda匿名函数 lambda表达式的定义 定义匿名函数:lambda 参数列表: 函数返回值
1 2 3 4 5 6 def add (x, y ): return x + y print (add(1 , 2 )) f = lambda x, y: x + y print (f(1 , 2 ))
三元表达式 其他语言中x > y ? x : y
Python中x if x > y else y也就是
条件为真时返回的结果 if 条件判断 else 条件为假时的返回结果
1 2 f = lambda x, y : x if x > y else y print (f(1 , 2 ))
map类 map(函数, 集合),map会把集合里面的所有元素都传入函数,然后返回一个map对象,里面保存了结果
map配合lambda 单参数:
1 2 3 4 5 6 7 8 9 10 list_x = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ] def square (x ): return x * x r = map (square, list_x) print (list (r)) r = map (lambda x : x * x, list_x) print (list (r))
多参数:
1 2 3 4 5 list_x = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ] list_y = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ] r = map (lambda x, y : x * x + y, list_x, list_y) print (list (r))
结果列表的元素个数取决于传入的比较小的集合的长度:
1 2 3 4 5 list_x = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ] list_y = [1 ,2 ,3 ,4 ,5 ,6 ] r = map (lambda x, y : x * x + y, list_x, list_y) print (list (r))
reduce函数 reduce函数:每一次lambda表达式的结果,将作为下一次调用lambda的参数去计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from functools import reducelist_x = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ] r = reduce(lambda x, y : x + y, list_x) print (r) ''' 第一次调用:x = 1, y = 2, x + y = 3 第二次调用:x = 3, y = 3, x + y = 6 第三次调用:x = 6, y = 4, x + y = 10 第四次调用:x = 10, y = 5, x + y = 15 第五次调用:x = 15, y = 6, x + y = 21 第六次调用:x = 21, y = 7, x + y = 28 第七次调用:x = 28, y = 8, x + y = 36 '''
第三个参数:初始值
1 2 3 4 5 6 7 from functools import reducelist_x = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ] r = reduce(lambda x, y : x + y, list_x, 10 ) print (r)
1 2 3 4 5 6 7 from functools import reducelist_x = ['1' ,'2' ,'3' ] r = reduce(lambda x, y : x + y, list_x, 'aaa' ) print (r)
filter类 filter传入的函数必须返回真或者假,为真,元素保留,为假,剔除此元素
1 2 3 4 5 list_x = [0 , 1 , 0 , 1 , 0 , 0 , 1 ] r = filter (lambda x: True if x == 1 else False , list_x) print (list (r))
装饰器 优点 稳定性:想对被封装的单元做出代码上的修改,可以不改变具体的单元实现,而是通过装饰器,改变函数的行为
复用性:可以加在多个函数上,增加这个功能装饰器
体现了AOP的编程思想
开闭原则:对修改是封闭的,对拓展是开放的
打印时间戳:
1 2 3 4 5 6 7 8 import timedef f1 (): print (time.time()) print ('This is a function' ) f1()
用单独的函数打印时间:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import timedef f1 (): print ('This is a function' ) def f2 (): print ('This is a function' ) def print_current_time (func ): print (time.time()) func() print_current_time(f1) print_current_time(f2) ''' 1662212278.4627192 This is a function 1662212278.4637156 This is a function '''
用装饰器打印时间:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import timedef decorator (func ): def wrapper (): print (time.time()) func() return wrapper def f1 (): print ('This is a function' ) f = decorator(f1) f() ''' 1662212710.1250434 This is a function '''
@语法糖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import timedef decorator (func ): def wrapper (): print (time.time()) func() return wrapper @decorator def f1 (): print ('This is a function' ) f1()
接收可变参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import timedef decorator (func ): def wrapper (*args ): print (time.time()) func(*args) return wrapper @decorator def f1 (func_name ): print ('This is a function ' + func_name) @decorator def f2 (func_name1, func_name2 ): print ('This is a function ' + func_name1) print ('This is a function ' + func_name2) f1('test func' ) f2('test func1' , 'test func2' )
接收关键字参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import timedef decorator (func ): def wrapper (*args, **kw ): print (time.time()) func(*args, **kw) return wrapper @decorator def f1 (func_name ): print ('This is a function ' + func_name) @decorator def f2 (func_name1, func_name2 ): print ('This is a function ' + func_name1) print ('This is a function ' + func_name2) @decorator def f3 (func_name1, func_name2, **kw ): print ('This is a function ' + func_name1) print ('This is a function ' + func_name2) print (kw) f1('test func' ) f2('test func1' , 'test func2' ) f3('test func1' , 'test func2' , a=1 , b=2 , c='123' )
Python技巧 用字典映射代替switch case语句 不用下标访问,而是用get方法访问,第一个参数是key,第二个参数是如果key不存在的时候,将返回的结果
1 2 3 4 5 6 7 8 9 10 11 12 day = 6 switcher = { 0 : 'Sunday' , 1 : 'Monday' , 2 : 'Tuesday' } day_name = switcher.get(day, 'Unkown' ) print (day_name)
函数名+()调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 day = 6 def get_sunday (): return 'Sunday' def get_monday (): return 'Monday' def get_Tuesday (): return 'Tuesday' def get_unkown (): return 'Unkown' switcher = { 0 : get_sunday, 1 : get_monday, 2 : get_Tuesday } day_name = switcher.get(day, get_unkown)() print (day_name)
列表推导式 1 2 3 4 a = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ] b = [i**2 for i in a] print (b)
有条件的列表推导式 1 2 3 4 a = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ] b = [i**2 for i in a if i >= 5 ] print (b)
集合推导式 1 2 3 4 a = {1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 } b = {i**2 for i in a if i >= 5 } print (b)
元组推导式 为什么会得到一个generator对象呢?因为元组是不可变的
1 2 3 4 5 a = (1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ) b = (i**2 for i in a if i >= 5 ) for item in b: print (item, end=' ' )
字典推导式 得到key的列表:
1 2 3 4 5 6 7 8 students = { '喜小乐' :18 , '石敢当' :20 , '横小五' :15 } b = [key for key,value in students.items()] print (b)
颠倒key,value:
1 2 3 4 5 6 7 8 students = { '喜小乐' :18 , '石敢当' :20 , '横小五' :15 } b = {value:key for key,value in students.items()} print (b)
item方法: 返回可遍历的(键, 值) 元组数组
1 2 3 4 5 6 7 8 9 students = { '喜小乐' :18 , '石敢当' :20 , '横小五' :15 } s = students.items() print (type (s)) print (s)
key变元组: 为什么会得到一个generator对象呢?因为元组是不可变的
1 2 3 4 5 6 7 8 9 10 students = { '喜小乐' :18 , '石敢当' :20 , '横小五' :15 } b = (key for key,value in students.items()) print (b) for x in b: print (x, end=' ' )
None 从类型和值这两个方面来讲,None不等于不等于空字符串,不等于空列表,不等于0,不等于False
空本身也是一个对象,也是一个类型
1 2 3 4 5 6 7 8 9 10 11 12 13 a = '' b = False c = [] print (a == None ) print (b == None ) print (c == None ) print (a is None ) print (b is None ) print (c is None ) print (type (None ))
对象存在并不一定是True None对应的是False:
1 2 3 4 if None : print (1 ) else : print (0 )
一般除了None以外的对象是True:
1 2 3 4 5 6 7 class Test (): pass test = Test() if test: print ('S' )
对象存在,但是也被转化为False的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Test (): def __len__ (self ): return 0 test = Test() print (bool (None )) print (bool ([])) print (bool (test)) if test: print ('S' ) else : print ('F' )
__len__与__bool__内置方法 其实len()和bool()函数,实际上都是调用了类内部的__len__方法
如果没有定义bool和len方法,则这个对象会被认为是True
1 2 3 4 5 6 class Test (): pass test = Test() print (bool (test))
如果len方法返回的是0,则对象被认为是False
len方法只能返回整型和布尔值,返回其他会报错
1 2 3 4 5 6 7 class Test (): def __len__ (self ): return 0 test = Test() print (bool (test))
如果__bool__方法存在,那么__len__方法将不再影响bool的取值
1 2 3 4 5 6 7 8 9 class Test (): def __len__ (self ): return 0 def __bool__ (self ): return True test = Test() print (bool (test))
为什么__bool__方法存在,那么__len__方法将不再影响bool的取值呢?
因为如果__bool__方法存在,那么bool(test)的时候,__len__方法将不再被调用
1 2 3 4 5 6 7 8 9 10 class Test (): def __len__ (self ): print ('called' ) return 0 def __bool__ (self ): return True test = Test() print (bool (test))
__bool__方法只能返回bool,也就是True或者False,如果返回整型,也会报错