爬虫前奏 明确目的:爬取虎牙直播LOL板块主播人气排行
找到数据对应的网页
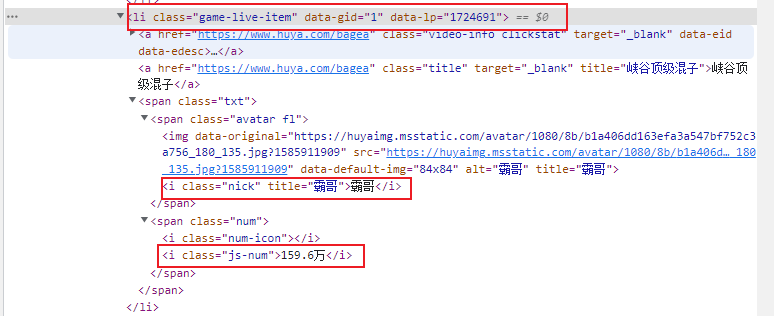
分析网页的结构找到数据所在的标签位置
模拟HTTP请求,向服务器发送这个请求,获取到服务器返回给我们的HTML
用正则表达式提取我们要的数据(名字,人气)
初始化获取html的类和方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from urllib import requestclass Spider (): url = 'https://www.huya.com/g/lol' def __fetch_content (self ): r = request.urlopen(Spider.url) htmls = r.read() def go (self ): self.__fetch_content() spider = Spider() spider.go()
vscode断点调试 如果Python和Pylance插件版本太高,断点可能会停不下来。
解决方案,Python退回到2020.9月版本,Pylance退回到2020.9.5版本
快捷键 启动调试:F5
单步调试:F10
从一个断点跳到下一个断点:F5
进入某个函数或者对象的内部:F11
编码转换 将字节码转换为字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from urllib import requestclass Spider (): url = 'https://www.huya.com/g/lol' def __fetch_content (self ): r = request.urlopen(Spider.url) htmls = r.read() htmls = str (htmls, encoding='utf-8' ) a = 1 def go (self ): self.__fetch_content() spider = Spider() spider.go()
分析爬到的内容 寻找合适的定位标签 找离需要爬取的数据最近的一个标签,并且标签要具有唯一性
标签最好是选择能够闭合的标签(父级标签)
逐级精确定位,三层结构:
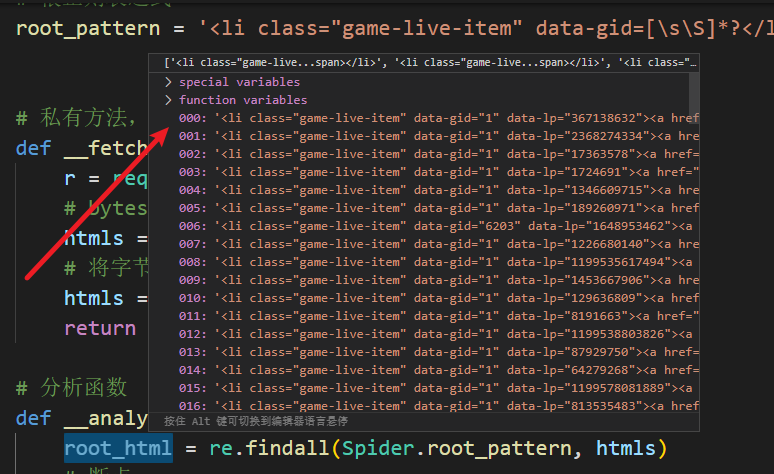
编写正则表达式 根正则表达式 1 root_pattern = '<li class="game-live-item" data-gid=([\s\S]*?)</li>'
分析成功:
姓名和人数的正则表达式 1 2 name_pattern = '<i class="nick" title="([\s\S]*?)">' number_pattern = '<i class="js-num">([\s\S]*?)</i>'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import refrom urllib import requestclass Spider (): url = 'https://www.huya.com/g/lol' root_pattern = '<li class="game-live-item" data-gid=([\s\S]*?)</li>' name_pattern = '<i class="nick" title="([\s\S]*?)">' number_pattern = '<i class="js-num">([\s\S]*?)</i>' def __fetch_content (self ): r = request.urlopen(Spider.url) htmls = r.read() htmls = str (htmls, encoding='utf-8' ) return htmls def __analysis (self, htmls ): root_html = re.findall(Spider.root_pattern, htmls) anchors = [] for html in root_html: name = re.findall(Spider.name_pattern, html) number = re.findall(Spider.number_pattern, html) anchor = {'name' :name, 'number' :number} anchors.append(anchor) print (anchors) a = 1 def go (self ): htmls = self.__fetch_content() self.__analysis(htmls) spider = Spider() spider.go()
数据精炼 strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import refrom urllib import requestclass Spider (): url = 'https://www.huya.com/g/lol' root_pattern = '<li class="game-live-item" data-gid=([\s\S]*?)</li>' name_pattern = '<i class="nick" title="([\s\S]*?)">' number_pattern = '<i class="js-num">([\s\S]*?)</i>' def __fetch_content (self ): r = request.urlopen(Spider.url) htmls = r.read() htmls = str (htmls, encoding='utf-8' ) return htmls def __analysis (self, htmls ): root_html = re.findall(Spider.root_pattern, htmls) anchors = [] for html in root_html: name = re.findall(Spider.name_pattern, html) number = re.findall(Spider.number_pattern, html) anchor = {'name' :name, 'number' :number} anchors.append(anchor) return anchors def __refine (self, anchors ): l = lambda anchor: { 'name' :anchor['name' ][0 ].strip(), 'number' :anchor['number' ][0 ].strip() } return map (l, anchors) def go (self ): htmls = self.__fetch_content() anchors = self.__analysis(htmls) anchors = list (self.__refine(anchors)) print (anchors) spider = Spider() spider.go()
排序 排序函数:
sorted(集合, key=排序的种子, 升序还是降序)
sorted(anchors, key=self.__sort_seed, reverse=True)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 from os import read, readlinkimport refrom urllib import requestclass Spider (): url = 'https://www.huya.com/g/lol' root_pattern = '<li class="game-live-item" data-gid=([\s\S]*?)</li>' name_pattern = '<i class="nick" title="([\s\S]*?)">' number_pattern = '<i class="js-num">([\s\S]*?)</i>' def __fetch_content (self ): r = request.urlopen(Spider.url) htmls = r.read() htmls = str (htmls, encoding='utf-8' ) return htmls def __analysis (self, htmls ): root_html = re.findall(Spider.root_pattern, htmls) anchors = [] for html in root_html: name = re.findall(Spider.name_pattern, html) number = re.findall(Spider.number_pattern, html) anchor = {'name' :name, 'number' :number} anchors.append(anchor) return anchors def __refine (self, anchors ): l = lambda anchor: { 'name' :anchor['name' ][0 ].strip(), 'number' :anchor['number' ][0 ].strip() } return map (l, anchors) def __sort (self, anchors ): anchors = sorted (anchors, key=self.__sort_seed, reverse=True ) return anchors def __sort_seed (self, anchor ): r = re.findall('\d*' , anchor['number' ]) r = r[0 ] + '.' + r[2 ] number = float (r) if '万' in anchor['number' ]: number *= 10000 return number def __show (self, anchors ): for rank in range (0 , len (anchors)): print ('rank: ' + str (rank + 1 ) + ' | name: ' + anchors[rank]['name' ] + ' | number: ' + anchors[rank]['number' ]) def go (self ): htmls = self.__fetch_content() anchors = self.__analysis(htmls) anchors = list (self.__refine(anchors)) anchors = self.__sort(anchors) self.__show(anchors) spider = Spider() spider.go()